How Spotify knows exactly what you want to listen to
Rachel Huang. 07/10/2021

Spotify. As the biggest music streaming platform in the world, Spotify has two main advantages over its competitors: its large and diverse reserves of music consisting of over 70 million songs and its ability to figure out exactly what you want to listen to. Utilizing a search engine that combines multiple machine learning and data analysis models, Spotify collects data from your playlists and then finds similar songs to recommend to you. The personalization of Spotify can be broken down into two main parts: its data infrastructure and personalization algorithm.
Data Infrastructure
Open-source Apache software platforms Kafka, Storm, Crunch, and Cassandra make up the foundation of Spotify. These software systems seamlessly work together to collect and analyze data in real-time and then store it in user profiles as personalized suggestions according to the user’s preference. To make up Spotify’s personalization tech stack (in computing, a stack is a data structure used for storage), a sequence composed of these software systems is run: Kafka collects data, Storm and Hadoop Distributed File System (HDFS) process the data in real-time, Crunch further processes the data, and everything is stored in Cassandra.
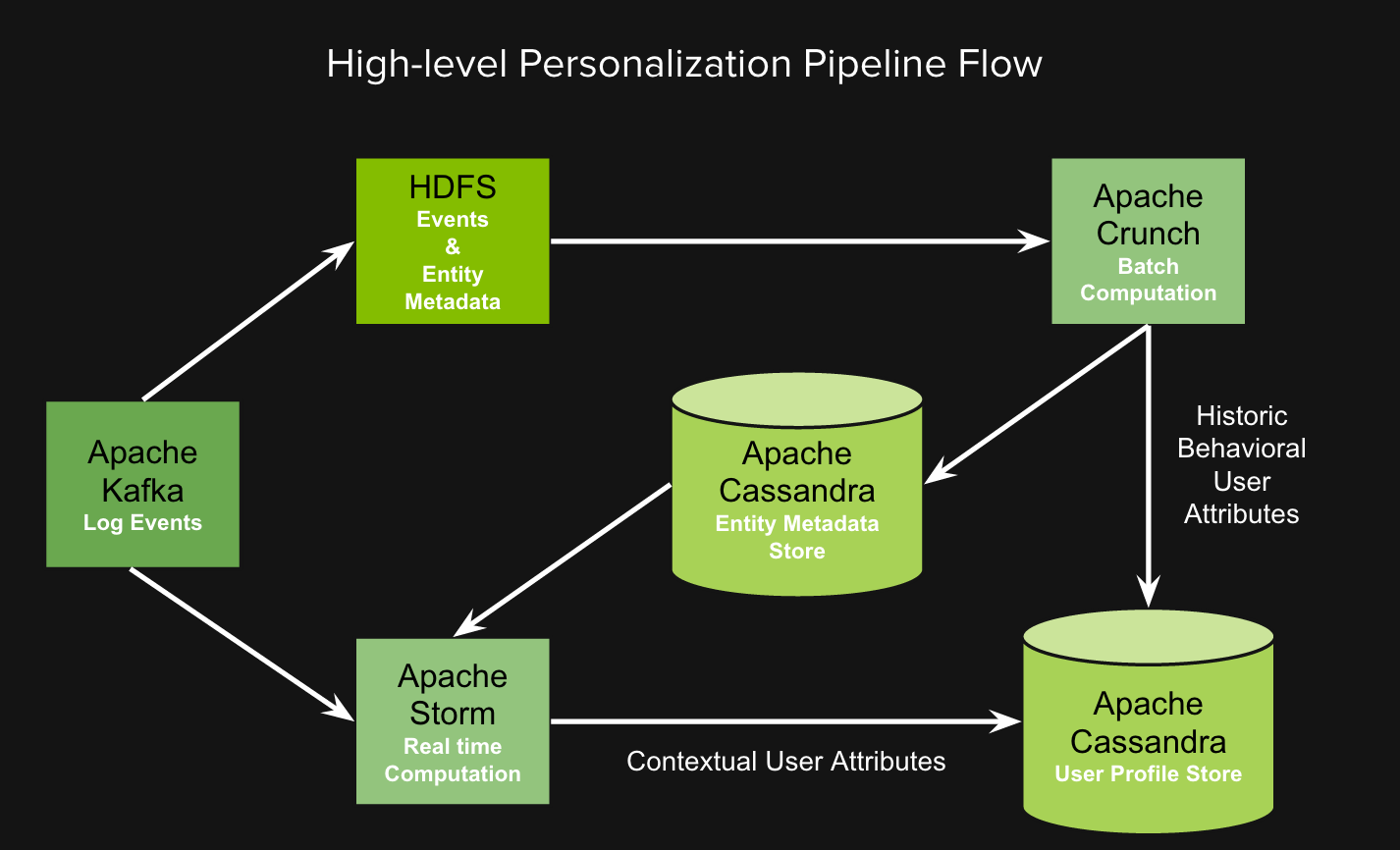
The Cassandra database, Spotify’s storage unit, consists of over 100 Cassandra clusters, each containing a nested storage system within itself. The sequential layering of the shells can be represented as follows: cluster → nodes → keyspace → column families→ rows → column. The nodes are made up of computers that share data with each other, and each subsequent shell is a more specific classification of the data in the shell before it. User profile attributes and metadata about playlists and artists are stored in Cassandra clusters.
How the Personalization Algorithm Works
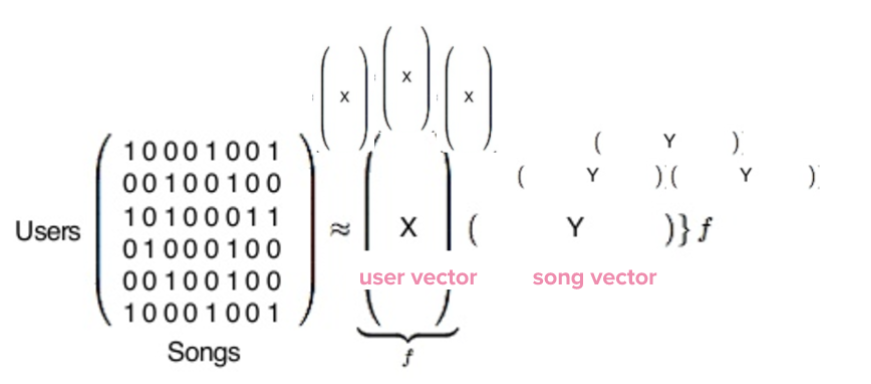
A popular feature of Spotify is the Discover Weekly playlist, a mixtape of 30 new songs that is updated every Monday. This playlist is the best example of Spotify’s personalization algorithm as its songs are directly determined by Spotify’s discovery engine, a mesh of the three data analysis models Collaborative Filtering, Natural Language Processing (NLP), and Audio Analysis. The Collaborative Filtering models rely on data that is stored in immense matrices containing millions of rows and columns, each row representing a user and each column representing a song. After running a matrix factorization formula (with Python libraries) on the user-song matrix, two vectors are produced. The first vector represents a user’s taste in music, and the second vector represents a song’s characteristics. These two vectors are unique to each user, and Spotify recommends songs by comparing your vector to other users’ vectors to find new songs that are similar to the music you are already listening to.
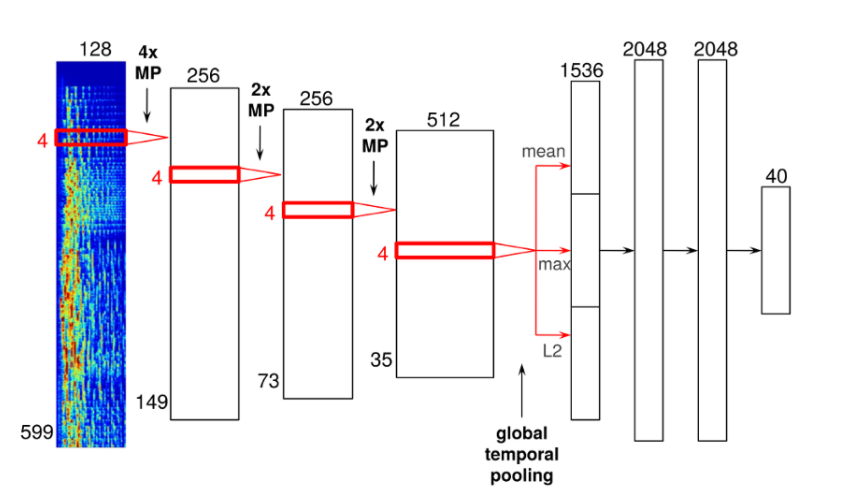
While the Collaborative Filtering models analyze data that is solely from Spotify, the NLP models analyze text on the internet about the songs in Spotify’s database, whether it be news articles about popular artists or tweets about new music. The NLP models use sentiment analysis APIs to create vectors from this collected text that can then be compared to determine if two pieces of music are culturally similar to one another. Finally, audio models analyze the raw audio tracks themselves, an “equalizing” measure built into Spotify’s recommendation models that provide new artists with the same chances of being placed into a user’s Discover Weekly playlist compared to popular artists since audio analysis doesn’t discriminate against song popularity. The audio models use convolutional neural networks to analyze the soundtracks of songs by inputting data as time-frequency representations of audio frames. The frames are then concatenated to form a spectrogram and passed through the convolutional layers of the model, ultimately computing the representative statistics of the song, like the time signature, key, and tempo.
Where the Discover Weekly Playlist is a representative slice of Spotify’s personalization ability, Spotify’s Home Screen is the whole “personalized experience” pie. The Home Screen is organized like a bookcase with each shelf (or each horizontal section) displaying your favorite books (the square images that represent playlists, podcasts, artists, albums, etc., more formally known as cards). Each user’s bookcase is different as it is based on their most recent activity, favorite playlists, new releases, and custom mixtapes such as the Discover Weekly Playlist. The cards in each shelf are constantly updated with the help of machine learning. In this case, machine learning can be divided into two sections, exploitation and exploration. Exploitation displays the cards based on your previous activity, whether it be the playlist you last listened to or the artist you started following recently. On the other hand, the exploration aspect is based on initiating user engagement by displaying suggested content, seeing how users respond, and then modifying the suggested content according to user interaction.
As younger generations can attest, the music industry is now centered on digitally streaming music. For example, the International Federation of the Phonographic Industry’s reports show that music streaming made up 62% of the 2020 global music industry, raking in a grand total of $13.4 billion for artists and labels worldwide. Spotify is at the forefront of this streaming movement with a user community of 356 million people that continues to grow every day. Spotify is necessary for singers to flourish, because their music has the possibility of being recommended to anybody and everybody, thanks to Spotify’s song analysis algorithms. 30% of plays on Spotify are credited to personalized recommendations, which serves as evidence of how Spotify is truly at the intersection of the roads of personalization and technology.
With Spotify continuing to push the boundaries of what music streaming can be, the only limit to the music industry is our imagination.
Cover Photo: (Pinterest)
